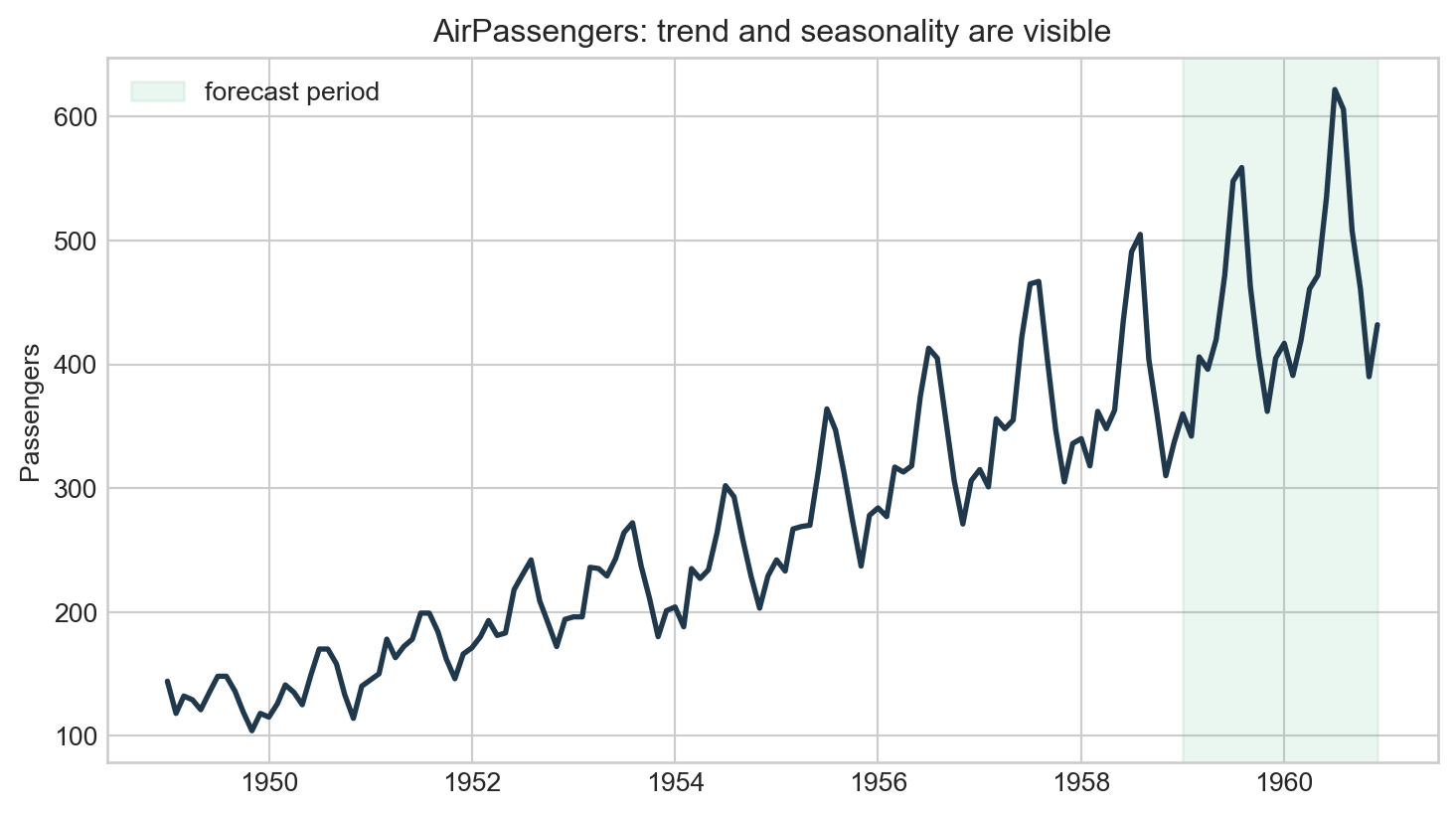
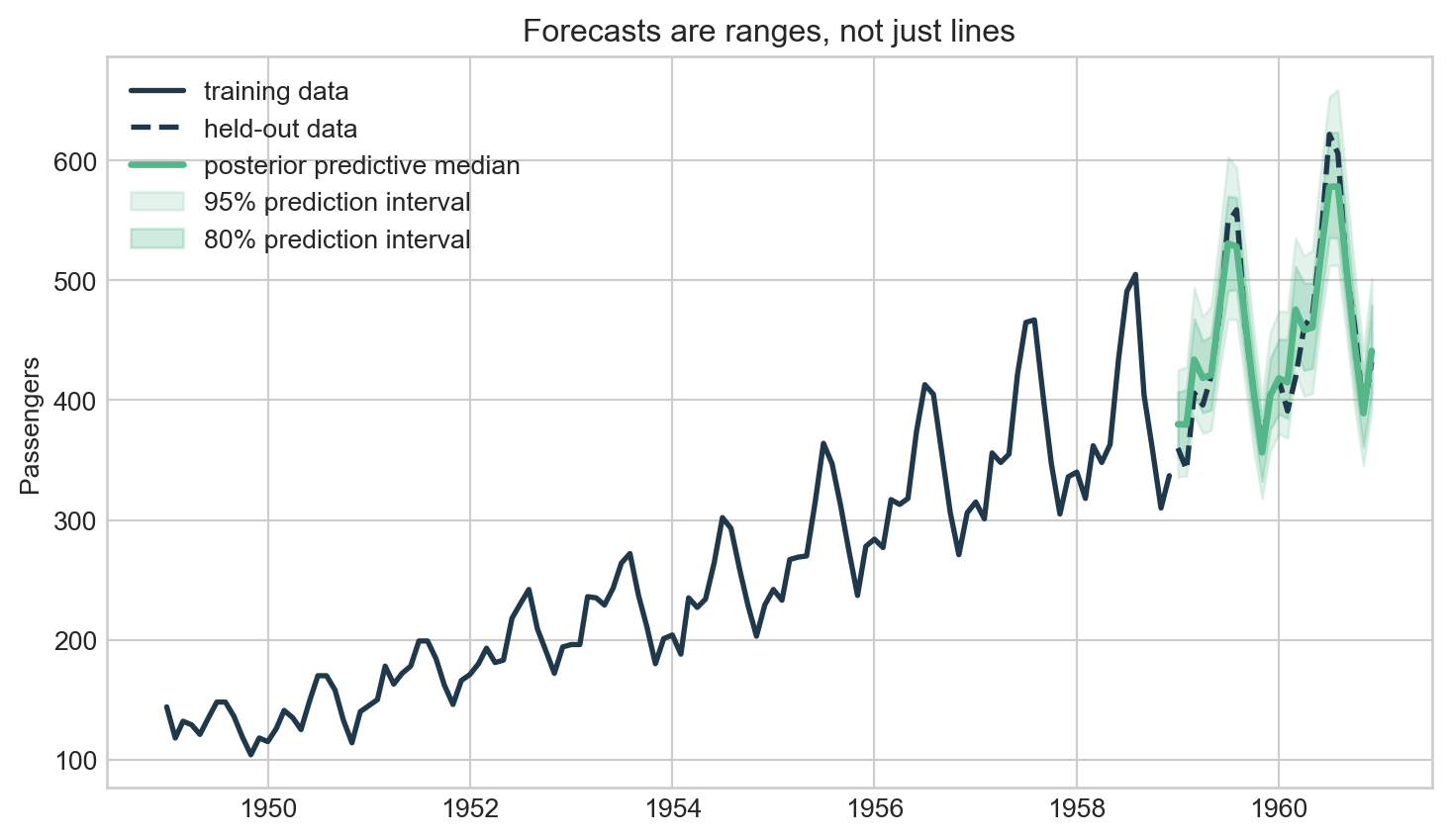
# Embed the classic AirPassengers series so the article is self-contained.
air_passengers = [
144, 118, 132, 129, 121, 135, 148, 148, 136, 119, 104, 118,
115, 126, 141, 135, 125, 149, 170, 170, 158, 133, 114, 140,
145, 150, 178, 163, 172, 178, 199, 199, 184, 162, 146, 166,
171, 180, 193, 181, 183, 218, 230, 242, 209, 191, 172, 194,
196, 196, 236, 235, 229, 243, 264, 272, 237, 211, 180, 201,
204, 188, 235, 227, 234, 264, 302, 293, 259, 229, 203, 229,
242, 233, 267, 269, 270, 315, 364, 347, 312, 274, 237, 278,
284, 277, 317, 313, 318, 374, 413, 405, 355, 306, 271, 306,
315, 301, 356, 348, 355, 422, 465, 467, 404, 347, 305, 336,
340, 318, 362, 348, 363, 435, 491, 505, 404, 359, 310, 337,
360, 342, 406, 396, 420, 472, 548, 559, 463, 407, 362, 405,
417, 391, 419, 461, 472, 535, 622, 606, 508, 461, 390, 432,
]
df = pd.DataFrame({
"date": pd.date_range("1949-01-01", periods=len(air_passengers), freq="MS"),
"passengers": air_passengers,
})
# The log scale turns multiplicative growth and seasonality into an additive model.
df["log_passengers"] = np.log(df["passengers"])
df["t"] = np.arange(len(df))
df["month"] = df["date"].dt.month - 1
# Hold out the final 24 months so interval coverage can be checked honestly.
train = df.iloc[:-24].copy()
test = df.iloc[-24:].copy()